In recent years, the financial industry has experienced a significant transformation with the introduction of automated decision-making systems powered by Machine Learning (ML). One of the critical applications of ML in the financial sector is loan approval forecasting, where traditional manual decision-making processes are augmented or replaced by data-driven models. The goal of this project is to predict loan approval decisions based on a range of applicant features, including personal information such as income, credit score, employment history, and loan characteristics, to enhance the efficiency and accuracy of loan approval processes.
This project utilizes machine learning algorithms to automate and enhance the loan approval process. By analyzing key factors such as income, credit history, employment status, and loan amount, the model predicts whether an applicant is eligible for a loan. Various classification algorithms, including Logistic Regression, Decision Trees, and Random Forest, are employed to achieve high accuracy. This data-driven approach improves efficiency, reduces manual errors, and ensures fair decision-making in loan approvals.
Existing System
The traditional loan approval process in financial institutions relies on manual evaluation by loan officers. Applicants submit their financial details, including income, credit history, employment status, and debt obligations. The loan officers then assess the eligibility based on predefined rules and guidelines.
However, this system has several limitations:
Time-Consuming – Manual verification and evaluation can be slow, leading to delays in loan approval.
Prone to Human Errors & Bias – Decisions may be inconsistent due to subjective judgment by loan officers.
Limited Data Utilization – Traditional methods fail to leverage large datasets for better insights and accuracy.
High Risk of Defaults – Due to inefficient risk assessment, loans may be granted to ineligible applicants, increasing financial losses.
These challenges highlight the need for an automated and data-driven approach using machine learning to improve loan approval forecasting.
Drawbacks
While machine learning improves loan approval forecasting, the system has some limitations:
Data Dependency – The accuracy of predictions depends heavily on the quality and quantity of training data. Poor or biased data can lead to incorrect results.
Feature Selection Challenges – Identifying the most relevant factors influencing loan approval can be complex and requires domain expertise.
Black Box Nature – Some advanced machine learning models, like deep learning and ensemble methods, lack interpretability, making it difficult to explain decisions to applicants and regulators.
Overfitting Risk – The model may perform well on training data but fail to generalize to new or unseen data, leading to poor real-world performance.
Ethical and Legal Concerns – If the training data contains historical biases, the model may unintentionally discriminate against certain groups, raising fairness and compliance issues.
Continuous Maintenance Required – The model needs regular updates to stay accurate, especially as financial trends, policies, and customer behaviors change.
Despite these challenges, machine learning can significantly enhance loan approval forecasting when combined with careful data preprocessing, feature engineering, and model evaluation techniques.
Proposed System
The proposed system leverages machine learning algorithms to automate and improve the loan approval forecasting process. By analyzing key factors such as income, credit history, employment status, loan amount, and debt-to-income ratio, the model predicts whether an applicant is eligible for a loan with high accuracy.
Key Features of the Proposed System:
Increased Prediction Accuracy – The system uses advanced machine learning techniques, such as Random Forest, XGBoost, and Neural Networks, with feature selection and hyperparameter tuning to enhance accuracy.
Automated Decision-Making – Reduces manual intervention, speeding up the loan approval process while ensuring consistency.
Data-Driven Risk Assessment – Identifies high-risk applicants by analyzing past loan approval patterns, helping financial institutions minimize default risks.
Fair and Transparent Evaluation – Reduces human bias by making decisions based on historical data patterns and statistical analysis.
Real-Time Prediction – Enables lenders to quickly assess applicants and provide near-instant loan approval decisions.
This system ensures efficient, accurate, and fair loan approvals, benefiting both financial institutions and applicants while reducing loan default risks.
Advantages of the Proposed System
Increased Prediction Accuracy – The use of advanced machine learning algorithms like Random Forest, XGBoost, and Neural Networks improves loan approval forecasting accuracy.
Faster Loan Processing – Automating the decision-making process reduces manual work and speeds up loan approvals.
Reduced Human Bias – Decisions are based on data-driven insights, minimizing subjective judgment and discrimination.
Improved Risk Assessment – The system analyzes financial history and identifies high-risk applicants, helping to reduce loan default rates.
Efficient Handling of Large Data – Machine learning models can process and analyze large datasets efficiently, improving decision-making.
Better Customer Experience – Faster and more accurate loan approval processes enhance customer satisfaction.
Cost-Effective – Reducing manual work lowers operational costs for financial institutions.
Adaptive Learning – The system can be updated with new data to improve predictions over time, adapting to changing financial trends.
This automated and intelligent system ensures fair, fast, and efficient loan approvals, benefiting both financial institutions and borrowers.
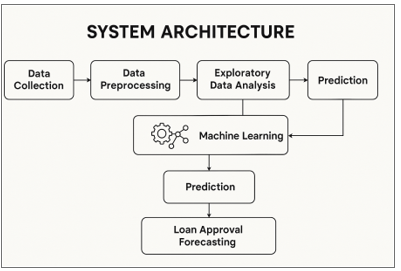
Working Principle
The proposed system follows a data-driven approach to predict loan approval using machine learning techniques. The working principle consists of the following key steps:
Data Collection – Gather historical loan application data, including applicant details such as income, credit score, employment status, loan amount, and repayment history.
Data Preprocessing – Clean and process the dataset by handling missing values, encoding categorical variables, and normalizing numerical data to improve model efficiency.
Feature Selection & Engineering – Identify the most important factors influencing loan approval and create new meaningful features to enhance model accuracy.
Model Selection & Training – Train machine learning models such as Logistic Regression, Decision Trees, Random Forest, XGBoost, or Neural Networks on the processed data to learn approval patterns.
Model Evaluation & Optimization – Assess model performance using metrics like accuracy, precision, recall, and F1-score and fine-tune it using hyperparameter optimization to improve results.
Loan Approval Prediction – Once trained, the model predicts whether a new loan application should be approved or rejected based on input features.
Deployment & Real-Time Prediction – Integrate the trained model into a system that allows lenders to input applicant details and get instant loan eligibility results.
This system ensures faster, more accurate, and fair loan approval decisions, reducing risks for financial institutions while improving customer experience.
System Requirements
System Requirements is nothing but an minimum requirements needed to be satisfied or to be presented to run this project. This minimum system requirements will not be compromised by anything. This is an mandatory requirement that a system should must meet to ensure the smooth execution flow of the program and to avoid un-necessary lag and crashes.
Hardware Requirements
Processor : Intel i3 or equivalent.
Storage : 256 GB HDD or SSD.
Monitor : 15 inch VGA Color.
Mouse : Logitech Mouse.
Ram : 4 GB
Keyboard : Standard Keyboard
GPU :Integrated GPU
Internet : Basic internet connection
Software Requirements
Operating System : Windows 10/11.
Programming language : Python 3.x (Main Language)
Libraries :
Pandas – For Data Manipulation
Numpy –Numerical Operations
Scikit – Learn – Machine Learning models
Matplotlib/ Seaborn – Data Visualization
Xgboost, Lightgbm – For advanced ML models(Optional)
Joblib Or Pickle – Model saving/Loading
Tools & IDEs :
Jupyter Notebook / JupyterLab
Visual studio Code / PyCharm
Anaconda (Optional, but useful for managing environments)